July 20, 2023
ML1 - Intro to Statistical Learning

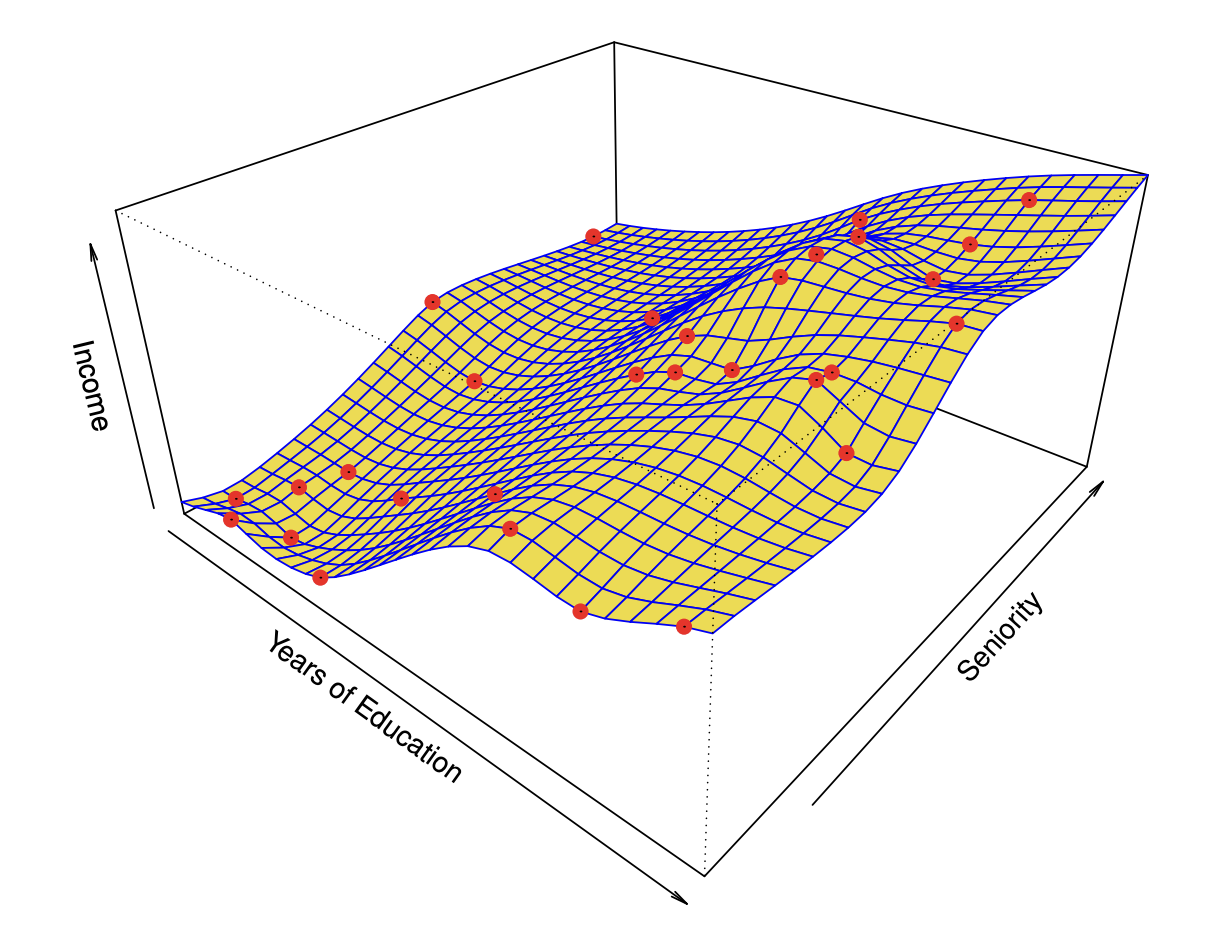
Tentang statistical learning
Machine learning memiliki cakupan yang sagat luas. Banyak metode, pendekatan, dan konsep mengenai machine learning yang beririsan dengan statistic. Statistical learning sangat terkait dengan dasar-dasar statistic as a "white-box" method dalam menyelesaikan masalah-masalah machine learning. Pada dasarnya tidak ada satu metode machine learning yang bisa kita gunakan untuk menyelesaikan semua masalah. Maka perlunya kemampuan untuk medeskripsikan model, memiliki intuisi, hipotesa, dan trade-off dari metode yang digunakan menjadi sangat penting.
Melalui pendekatan statistical learning, kita akan belajar bagaimana metode yang akan kita gunakan bekerja, the math behind. Jadi kita tidak hanya bisa mengaplikasikan metode tanpa tahu apa yang sebenarnya terjadi. Bukan karena metode yang kita gunakan bisa bekerja, tetapi karena berdasarkan pendekatan konseptual kenapa metode kita bisa bekerja. Dari data yang ada, lalu membuat hipotesa bahwa metode yang kita gunakan mampu menghasilkan luaran tertentu yang sesuai dengan hipotesis kita. Mudahnya, kita diharapkan memiliki kemampuan untuk mengestimasi akan seperti apa hasilnya.
Machine learning overview
Definisi Machine Learning sangat susah didefinisikan secara pasti. Karena didalamnya banyak metode dan pendekatan dari berbagai macam disiplin pengetahuan, dari statistics, computer science, pattern recognition, ataupun knowledge discovery. Jadi, machine learning lebih cocok masuk sebagai sebuah permasalahan daripada sebuah disiplin ilmu pengetahuan. Yakni masalah tentang data, pattern, dan prediksi.
Tetapi kita bisa berangkat dari definisi Tom Mitchell - 1997 tentang machine learning:
A computer program is said to learn from experience E with respect to some class of task T and a performance measure P, if its performance at tasks in T, as measured by P, improves because of experience E.
Dimana : Regression/Classification/Clustering etc, : Data, : Errors/Loss.
Kita akan membedakan machine learning berdasarkan kategori learning paradigm-nya. Asumsikan kita memiliki , adalah data,
bisa berbentuk skalar ataupun vektor. i.e. umur karyawan atau adalah tinggi dan berat karyawan. Selain itu kita juga memiliki data . i.e. Gaji karyawan dalam juta IDR atau dalam bentuk kategori . Ketika tugas kita memprediksi target berdasarkan input baru dengan yang baik, maka kita sebut ini sebagai Supervised Learning.
Jika kita hanya memiliki saja tanpa , maka kita kategorikan paradigma ini sebagai Unsupervised Learning, mencari regularities atau kesamaan pattern dari representasi data, untuk reasoning atau prediksi.
Paradigma lain yang mungkin akan kita pelajari pada series tulisan lain adalah Reinceforcement Learning. Dengan melakukan aksi yang mempengaruhi sistem, dimana setiap aksi berkaitan dengan reward yang kemudian kita gunakan sebagai parameter untuk memaksimalkan reward selanjutnya.
Supervised learning: Classification
, dimana adalah input, dan adalah target atau output. Handcrafted feature adalah karakteristik atau measurable property yang kita gunakan untuk mengidentifikasi suatu data. Learned classifier adalah hasil dari proses training atau biasa kita sebut dengan istilah Model. , jadi Model adalah suatu yang akan kita gunakan untuk memprediksi output atau (binary classification) berdasarkan input . Atau memprediski target , , atau (multiclass classification) berdasarkan input .
Supervised learning: Regression
Sama halnya dengan classification, , bedanya, adalah numerical value. Baik classification atau resgression, model adalah suatu fungsi . Sehingga learning suatu model sematically equivalent dengan learning suatu fungsi. Jika task kita adalah linear regression, maka kita learning fungsi linear. Jika polinomial regression, maka learning fungsi polinomial. Logistic regression, learning logistic function dst. Dimana pemilihan class function, kita yang akan menentukan. Itulah kenapa kita harus memiliki kemampuan untuk menentukan hipotesa dengan tepat, bahwa masalah ini bisa kita selesaikan dengan funsi linier, quadratic, atau polinomial, konsep ini kita kenal dengan istilah Inductive Hypothesis.
Unsupervised learning: Clustering
Misalkan kita memiliki data point Data point dapat kita representasikan ke dalam space pada titik koordinat . Kita bisa sebut vektor karena adalah magnitude dari origin ke titik seperti pada gambar.
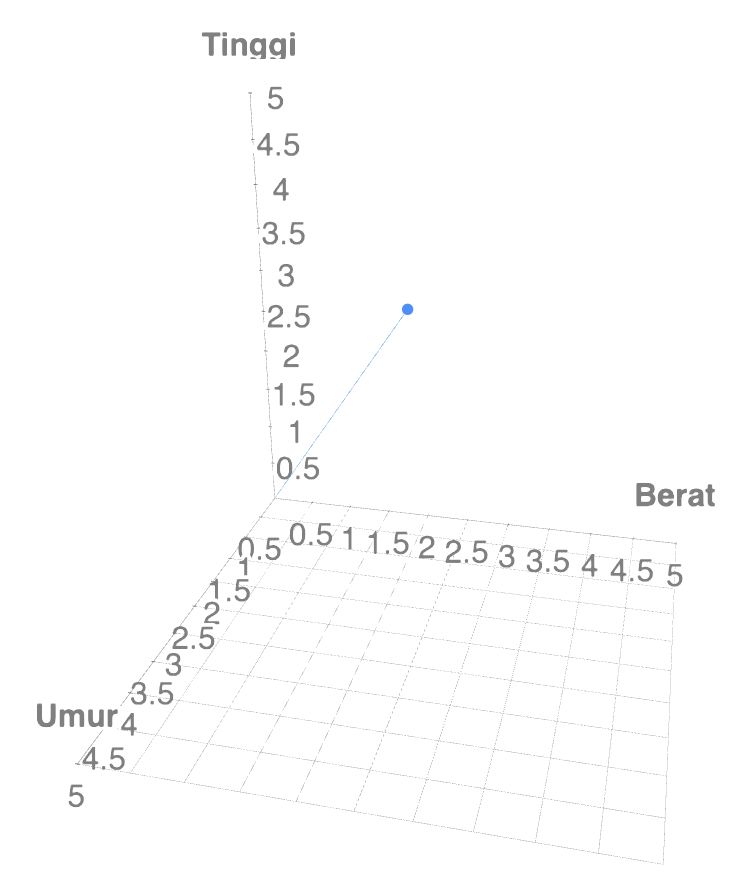
Jadi ketika kita melihat suatu data, kita dapat merepresentasikannya kedalam bentuk space. Dengan kata lain, kita bisa melihat setiap axis pada space adalah sebuah fitur dari data. Kombinasi dan transformasi axis dapat kita gunakan untuk mengalisa suatu data. Jika dimana memiliki p-dimensional space dan output adalah powerset dari . Maka clustering adalah pengelompokan atau partitioning berdasarkan kesamaan dari fiturnya.
References
[1] Machine Learning Lecture Prof. Matteo Matteucci
[2] The Element of Statistical Learning
[3] An Introduction to Statistical Learning